
15 November 2024

Forecasting stock returns can be tempting, it may sound like a good idea but it’s challenging to do accurately and consistently. It’s often best left to well-equipped institutions.
However, it is much easier to predict stock price volatility with a time-series model, for example, the GARCH model. That’s exactly what we are focusing on in this article today. We are going to find the best GARCH model to fit in terms of Autoregressive and Moving Average orders. Then we are going to fit this model and predict in a rolling window the variance of a stock for 1 step ahead, in our case that would be 1 day ahead. After we have all the predictions made, we would be able to compare them to the variance itself and try to form a tradable signal. Let’s get into it!
The development of a volatility model for the stock-returns series is done in four steps:
import matplotlib.pyplot as plt
import yfinance as yf
import pandas as pd
import numpy as np
stock_df = yf.download(tickers='NVDA', start='2012-01-01', end='2023-01-29')
stock_df
nvda_log_ret = np.log(stock_df['Adj Close']).diff().dropna()
nvda_daily_vol = (nvda_log_ret-nvda_log_ret.mean())**2
plot_correlogram(x=nvda_log_ret,
lags=120,
title='NVDA Daily Log Returns')
plot_correlogram(x=nvda_daily_vol,
lags=120,
title='NVDA Daily Volatility')

From those two plots, we can conclude that there is not enough valuable information into the lags of the log returns to build a reliable model, however, when we look at the daily volatility it looks much better with substantial information and autocorrelation in the lags up to and after 20.
Here the goal is to fit models with the different orders of Autoregression and Moving Averages, in an attempt to find the model which minimizes the RMSE and BIC. Then after we have found these model orders we can potentially use them to fit and predict in a rolling window.
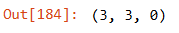
Our brute-force approach yields the conclusion that the best-performing model would be the one with AR order of 3 and MA order of 3.
data = nvda_log_ret.to_frame('nvda_log_ret')
data = data['2020':]
data['variance'] = data['nvda_log_ret'].rolling(70).var()
data['predictions'] = data['nvda_log_ret'].rolling(70).apply(lambda x: predict_volatility(x))
data
data[['variance', 'predictions']].plot(figsize=(16,4))
plt.title('Compare The Rolling Variance and The Predictions')
plt.show()
It’s looking somewhat good, but the predictions are really messy. What we can do here is just apply a Kalman filter on the predicted values to denoise them.
data['fixed_predictions'] = KalmanFilterAverage(data['predictions'])
data[['variance', 'fixed_predictions']].plot(figsize=(16,4))
plt.title('Compare The Rolling Variance and The FIXED Predictions')
plt.show()
Now the predictions look much better and promising 🙂

From this signal, I’ve created a long short strategy with up to a week of holding period.

print(f"Sharpe Ratio NVDA rets: {round((data['nvda_log_ret'].mean()/data['nvda_log_ret'].std())*(252**.5),2)}")
print(f"Sharpe Ratio strategy rets: {round((data['strategy_return'].mean()/data['strategy_return'].std())*(252**.5),2)}")
⚠️If you want to get the full code.⚠️
In this article, we explored how to fit a time-series model to successfully predict one day ahead stock variance. Furthermore, we learned how to do that in a rolling window and how to denoise the predictions. In the end, we created a strategy with a holding period of 5 days. If you enjoy such content and are interested in learning much more about algorithmic trading and developing algo trading strategies follow me for more content like this!
I hope this article is helpful! Let me know if you have any questions or if you would like further information on any of the topics covered.
Sources:
Stefan Jansen — Machine Learning for Algorithmic Trading


 BTC
BTC ETH
ETH USDT
USDT USDC
USDC TRX
TRX